
1. Supported formats#
This section lists the file format supported by the FeST model.
1.1. Raster map#
The FEST model supports natively three file formats for grid map:
ESRI ASCII grid
ESRI BINARY grid
NetCDF
1.1.1. ESRI ASCII grid#
The ESRI ASCII raster format file begins with header information that defines the properties of the raster such as the cell size, the number of rows and columns, and the coordinates of the origin of the raster. The header information is followed by cell value information specified in space-delimited row-major order, with each row separated by a carriage return.
The basic structure of the ESRI ASCII raster has the header information at the beginning of the file followed by the cell value data:
NCOLS xxx
NROWS xxx
XLLCORNER xxx
YLLCORNER xxx
CELLSIZE xxx
NODATA_VALUE xxx
row 1
row 2
...
row n
Warning
Currently the supplementary .prj file used to assign spatial reference system to the grid is not supported. Spatial reference information should be set in FEST configuration files.
1.1.1.1. Header format#
The syntax of the header information is a keyword paired with the value of that keyword. The definitions of the keywords are:
Parameter |
Description |
Requirements |
|---|---|---|
NCOLS |
Number of cell columns. |
Integer greater than 0. |
NROWS |
Number of cell rows. |
Integer greater than 0. |
XLLCORNER |
X coordinate of the origin by lower left corner of the cell |
Match with Y coordinate type. |
YLLCORNER |
Y coordinate of the origin by lower left corner of the cell |
Match with X coordinate type. |
CELLSIZE |
Cell size. |
Greater than 0. |
NODATA_VALUE |
The input values to be NoData in the output raster. |
Default is -9999 but a different value can be used |
1.1.1.2. Data format#
The data component of the ESRI ASCII raster follows the header information.
Cell values should be delimited by spaces.
No carriage returns are necessary at the end of each row in the raster. The number of columns in the header determines when a new row begins.
Row 1 of the data is at the top of the raster, row 2 is just under row 1, and so on.
1.1.2. ESRI BINARY grid#
ESRI BINARY grid is similar to ESRI ASCII grid, however, there are two differences. First, in ESRI BINARY grid the gridded data values are in binary form, typically resulting in smaller files. Second, ESRI BINARY grid is a pair of files: a simple text file with extension .hdr that contains the same information as the first six lines of the equivalent ESRI ASCII grid with one additional line; and the primary content of numeric values in binary form in a file with extension .flt. The two files are associated by sharing the filename before the period, e.g., myfile.flt and myfile.hdr.
1.1.2.1. Header format#
The header file defines the properties of the grid, such as the cell size, the number of rows and columns, and the coordinates of the origin of the rectangular grid. The header keywords can be in upper or lower case.
The syntax of the header information is a keyword paired with the value of that keyword. The definitions of the keywords are:
Parameter |
Description |
Requirements |
|---|---|---|
NCOLS |
Number of cell columns. |
Integer greater than 0. |
NROWS |
Number of cell rows. |
Integer greater than 0. |
XLLCORNER |
X coordinate of the origin by lower left corner of the cell |
Match with Y coordinate type. |
YLLCORNER |
Y coordinate of the origin by lower left corner of the cell |
Match with X coordinate type. |
CELLSIZE |
Cell size. |
Greater than 0. |
NODATA_VALUE |
The input values to be NoData in the output raster. |
Default is -9999 but a different value can be used |
BYTEORDER MSBFIRST or BYTEORDER LSBFIRST |
Specifying whether the values have the most significant byte first or the least significant byte first |
BYTEORDER LSBFIRST |
1.1.2.2. Data format#
The .flt file holds values for a single numeric measure, a value for each cell in the rectangular grid. The numeric values are in IEEE floating-point 32-bit (aka single-precision) signed binary format. The first number in the .flt file corresponds to the top left cell of the raster/grid. Going from left to right along the top row, the first 32 bits form the value for the first cell, the next 32 bits the value for the second cell, and so on, to the end of the top row. This is repeated for the second row of the raster, continuing to the lower right-hand cell.
1.1.3. NetCDF#
NetCDF (network Common Data Form) is a file format for storing multidimensional scientific data (variables) such as temperature, humidity, pressure, wind speed, and direction. NetCDF file has usually extenson .nc, however different extensions may be encountered.
NetCDF data is:
Self-Describing. A NetCDF file includes information about the data it contains.
Portable. A NetCDF file can be accessed by computers with different ways of storing integers, characters, and floating-point numbers.
Scalable. A small subset of a large dataset may be accessed efficiently.
Appendable. Data may be appended to a properly structured NetCDF file without copying the dataset or redefining its structure.
Sharable. One writer and multiple readers may simultaneously access the same NetCDF file.
The data in a NetCDF file is stored in the form of arrays. For example, temperature varying over time at a location is stored as a one-dimensional array. Temperature over an area for a given time is stored as a two-dimensional array.
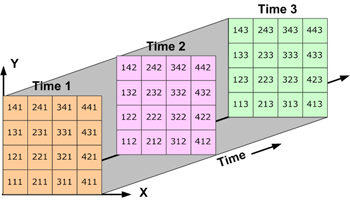
Fig. 1.1 three-dimensional data: Data over an area varying with time (source: http://pro.arcgis.com/en/pro-app/help/data/multidimensional/fundamentals-of-netcdf-data-storage.htm).#
Three-dimensional (3D) data, like temperature over an area varying with time, or four-dimensional (4D) data, like temperature over an area varying with time and altitude, is stored as a series of two-dimensional arrays.
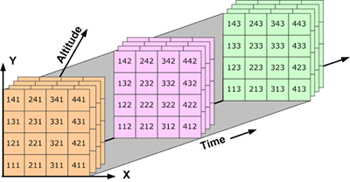
Fig. 1.2 three-dimensional data: Four-dimensional data: Data over an area varying with time and altitude (source: http://pro.arcgis.com/en/pro-app/help/data/multidimensional/fundamentals-of-netcdf-data-storage.htm)#
A NetCDF file contains dimensions, variables, and attributes. These components are used together to capture the meaning of data and relations among data fields in an array-oriented dataset.
Many organizations and scientific groups in different countries have adopted NetCDF as a standard way to represent some forms of scientific data, sometimes by defining a convention.
The conventions define metadata that provides a definitive description of the data in each variable and their spatial and temporal properties. A convention helps users of data from different sources to decide which quantities are comparable. The name of the convention is presented as a global attribute in a netCDF file. Currently, the Climate and Forecast (CF) (http://cfconventions.org/) is supported.
For more information about NetCDF, visit: http://www.unidata.ucar.edu/software/netcdf/
1.2. Spatial reference systems#
All maps of input parameters (i.e. the digital elevation model, soil saturated hydraulic conductivity, etc..) and site data (i.e. precipitation, air temperature, etc..) must be spatially referenced in either one of the supported Spatial Reference Systems (SRS).
List of supported projections:
Geodetic
Universal Transverse Mercator
Transverse Mercator
Gauss Boaga (Italy)
Hotine Oblique Mercator
Swiss Oblique Cylindrical
List of supported datums:
World Geodetic System 1984
European Datum 1950
Monte Mario
Swiss grid (CH1903)
Assignment of SRS is done within the input file for maps in NetCDF format and site data, or through the FEST configuration files for ESRI ASCII and ESRI BINARY grids. SRS assignment is done according to EPSG (http://www.epsg.org/).
List of accepted values:
4326 GEODETIC, WGS84
4230 GEODETIC, ED50
3003 Gauss Boaga West
3004 Gauss Boaga East
21781 CH1903 Swiss topo
23028 ED50 / UTM zone 28N
23029 ED50 / UTM zone 29N
23030 ED50 / UTM zone 30N
23031 ED50 / UTM zone 31N
23032 ED50 / UTM zone 32N
23033 ED50 / UTM zone 33N
23034 ED50 / UTM zone 34N
23035 ED50 / UTM zone 35N
23036 ED50 / UTM zone 36N
23037 ED50 / UTM zone 37N
23038 ED50 / UTM zone 38N
32601 WGS 84 / UTM zone 1N
32602 WGS 84 / UTM zone 2N
32603 WGS 84 / UTM zone 3N
32604 WGS 84 / UTM zone 4N
32605 WGS 84 / UTM zone 5N
32606 WGS 84 / UTM zone 6N
32607 WGS 84 / UTM zone 7N
32608 WGS 84 / UTM zone 8N
32609 WGS 84 / UTM zone 9N
32610 WGS 84 / UTM zone 10N
32611 WGS 84 / UTM zone 11N
32612 WGS 84 / UTM zone 12N
32613 WGS 84 / UTM zone 13N
32614 WGS 84 / UTM zone 14N
32615 WGS 84 / UTM zone 15N
32616 WGS 84 / UTM zone 16N
32617 WGS 84 / UTM zone 17N
32618 WGS 84 / UTM zone 18N
32619 WGS 84 / UTM zone 19N
32620 WGS 84 / UTM zone 20N
32621 WGS 84 / UTM zone 21N
32622 WGS 84 / UTM zone 22N
32623 WGS 84 / UTM zone 23N
32624 WGS 84 / UTM zone 24N
32625 WGS 84 / UTM zone 25N
32626 WGS 84 / UTM zone 26N
32627 WGS 84 / UTM zone 27N
32628 WGS 84 / UTM zone 28N
32629 WGS 84 / UTM zone 29N
32630 WGS 84 / UTM zone 30N
32631 WGS 84 / UTM zone 31N
32632 WGS 84 / UTM zone 32N
32633 WGS 84 / UTM zone 33N
32634 WGS 84 / UTM zone 34N
32635 WGS 84 / UTM zone 35N
32636 WGS 84 / UTM zone 36N
32637 WGS 84 / UTM zone 37N
32638 WGS 84 / UTM zone 38N
32639 WGS 84 / UTM zone 39N
32640 WGS 84 / UTM zone 40N
32641 WGS 84 / UTM zone 41N
32642 WGS 84 / UTM zone 42N
32643 WGS 84 / UTM zone 43N
32644 WGS 84 / UTM zone 44N
32645 WGS 84 / UTM zone 45N
32646 WGS 84 / UTM zone 46N
32647 WGS 84 / UTM zone 47N
32648 WGS 84 / UTM zone 48N
32649 WGS 84 / UTM zone 49N
32650 WGS 84 / UTM zone 50N
32651 WGS 84 / UTM zone 51N
32652 WGS 84 / UTM zone 52N
32653 WGS 84 / UTM zone 53N
32654 WGS 84 / UTM zone 54N
32655 WGS 84 / UTM zone 55N
32656 WGS 84 / UTM zone 56N
32657 WGS 84 / UTM zone 57N
32658 WGS 84 / UTM zone 58N
32659 WGS 84 / UTM zone 59N
32660 WGS 84 / UTM zone 60N
32701 WGS 84 / UTM zone 1S
32702 WGS 84 / UTM zone 2S
32703 WGS 84 / UTM zone 3S
32704 WGS 84 / UTM zone 4S
32705 WGS 84 / UTM zone 5S
32706 WGS 84 / UTM zone 6S
32707 WGS 84 / UTM zone 7S
32708 WGS 84 / UTM zone 8S
32709 WGS 84 / UTM zone 9S
32710 WGS 84 / UTM zone 10S
32711 WGS 84 / UTM zone 11S
32712 WGS 84 / UTM zone 12S
32713 WGS 84 / UTM zone 13S
32714 WGS 84 / UTM zone 14S
32715 WGS 84 / UTM zone 15S
32716 WGS 84 / UTM zone 16S
32717 WGS 84 / UTM zone 17S
32718 WGS 84 / UTM zone 18S
32719 WGS 84 / UTM zone 19S
32720 WGS 84 / UTM zone 20S
32721 WGS 84 / UTM zone 21S
32722 WGS 84 / UTM zone 22S
32723 WGS 84 / UTM zone 23S
32724 WGS 84 / UTM zone 24S
32725 WGS 84 / UTM zone 25S
32726 WGS 84 / UTM zone 26S
32727 WGS 84 / UTM zone 27S
32728 WGS 84 / UTM zone 28S
32729 WGS 84 / UTM zone 29S
32730 WGS 84 / UTM zone 30S
32731 WGS 84 / UTM zone 31S
32732 WGS 84 / UTM zone 32S
32733 WGS 84 / UTM zone 33S
32734 WGS 84 / UTM zone 34S
32735 WGS 84 / UTM zone 35S
32736 WGS 84 / UTM zone 36S
32737 WGS 84 / UTM zone 37S
32738 WGS 84 / UTM zone 38S
32739 WGS 84 / UTM zone 39S
32740 WGS 84 / UTM zone 40S
32741 WGS 84 / UTM zone 41S
32742 WGS 84 / UTM zone 42S
32743 WGS 84 / UTM zone 43S
32744 WGS 84 / UTM zone 44S
32745 WGS 84 / UTM zone 45S
32746 WGS 84 / UTM zone 46S
32747 WGS 84 / UTM zone 47S
32748 WGS 84 / UTM zone 48S
32749 WGS 84 / UTM zone 49S
32750 WGS 84 / UTM zone 50S
32751 WGS 84 / UTM zone 51S
32752 WGS 84 / UTM zone 52S
32753 WGS 84 / UTM zone 53S
32754 WGS 84 / UTM zone 54S
32755 WGS 84 / UTM zone 55S
32756 WGS 84 / UTM zone 56S
32757 WGS 84 / UTM zone 57S
32758 WGS 84 / UTM zone 58S
32759 WGS 84 / UTM zone 59S
32760 WGS 84 / UTM zone 60S
1.3. Date and time format#
The date and time string adheres to the International Standard ISO 8601 specifications. Date and time is expressed in the form YYYY-MM-DDThh:mm:ssTZD where:
YYYY = four-digit year
MM = two-digit month (01=January, etc.)
DD = two-digit day of month (01 through 31)
hh = two digits of hour (00 through 23) (am/pm NOT allowed)
mm = two digits of minute (00 through 59)
ss = two digits of second (00 through 59)
TZD = time zone designator (+hh:mm or -hh:mm)
A time zone offset of “+hh:mm” indicates that the date/time uses a local time zone which is “hh” hours and “mm” minutes ahead of UTC (Coordinated Universal Time). A time zone offset of -hh:mm indicates that the date/time uses a local time zone which is hh hours and mm minutes behind UTC.
Date and time example
2007-03-05T01:00:00+02:00
1.4. Time series of site data#
Time series of site data, such as precipitation or air temperature
data acquired by meteorological stations, are stored in plain text files.
File suffix assigned to the file is usually .fts (fest time series), but any suffix is allowed.
Every file contains data of the same variable of all available stations.
So, for performing an hydrological simulation you need to prepare one
file with all precipitation data available, one with air temperature
data, and so on. The time step must be regular along one file.
Time step can be different from file to file (for example hourly
precipitation and daily air temperature data are allowed).
In each file, the first 7 rows define general information of the included data in a key-value paradigm ( Table 1.3 ) ( see Configuration files: general tips ).
Key |
Description |
|---|---|
|
Describes data included |
|
Unit of data included |
|
EPSG code of data spatial reference system |
|
Total number of stations |
|
Time step in second |
|
Number for missing data value |
|
Station height above terrain in meter |
A section identified by the keyword metadata follows.
It marks the beginning of the station metadata information.
For each station the user must include, in the order, station name
(without blank spaces), station id, easting and northing coordinate, and elevation.
A section identified by the keyword data follows.
It marks the beginning of time series data. The first
line after the data keyword is a comment line usually
used to recall station id, but any kind of comment can
be included here without compromising the simulation.
The following lines after the comment line include the
date and time of the data, and the list of data acquired
by the stations in the same order used to list stations
in the metadata section.
Note that time steps must be perfectly regular (no any gap in date and time is allowed) and no any gap (blanck space) must be present in data section. When one data is missing, it must be substituted by the missing data value code. Data and strings are separated by one or more blank spaces or tabs. A dot (.) is used as decimal separator.
The next example shows a time series file that contains air temperature data from 3 stations at hourly time step for a total of 24 hours. Coordinate reference system is Monte Mario / Italy zone 1 (epsg code 3003), value for missing data is -999.9 and station height above terrain is 2 m.
Example of time series of site data file
description = air temperature
unit = degree_Celsius
epsg = 3003
count = 3
dt = 3600 # second
missing-data = -999.9
offsetz = 2 #station height above terrain(m)
metadata
station1 id1 1520147.2 5038191.3 120.4
station2 id2 1538227.4 5003859.6 80.7
station3 id3 1520740.5 5038780.8 120.5
data
time id1 id2 id3
2004-03-27T00:00:00+00:00 6.1 5.7 5.8
2004-03-27T01:00:00+00:00 5.6 5.6 5.5
2004-03-27T02:00:00+00:00 5.7 5.6 5.5
2004-03-27T03:00:00+00:00 5.5 5.4 5.3
2004-03-27T04:00:00+00:00 5.3 5.2 5.2
2004-03-27T05:00:00+00:00 5.4 5.1 5.3
2004-03-27T06:00:00+00:00 5.5 4.9 5.4
2004-03-27T07:00:00+00:00 5.7 -999.9 5.4
2004-03-27T08:00:00+00:00 5.7 -999.9 5.5
2004-03-27T09:00:00+00:00 5.8 5.5 5.7
2004-03-27T10:00:00+00:00 6.6 5.7 6.3
2004-03-27T11:00:00+00:00 7.1 6.5 6.9
2004-03-27T12:00:00+00:00 7.5 7.7 7.3
2004-03-27T13:00:00+00:00 7.9 8.7 7.5
2004-03-27T14:00:00+00:00 8.5 9.3 8.5
2004-03-27T15:00:00+00:00 9.9 9.3 9.6
2004-03-27T16:00:00+00:00 9.7 9.6 9.5
2004-03-27T17:00:00+00:00 9.1 8.8 9.2
2004-03-27T18:00:00+00:00 7.9 7.5 8.4
2004-03-27T19:00:00+00:00 6.8 6.3 8.2
2004-03-27T20:00:00+00:00 6.7 6.1 7.3
2004-03-27T21:00:00+00:00 6.8 6.0 7.2
2004-03-27T22:00:00+00:00 6.9 5.9 7.1
2004-03-27T23:00:00+00:00 6.9 5.7 6.9
1.5. Time series of generic variable#
Time series of generic variables, are stored in plain text files.
File suffix assigned to the file is usually .out (generic time series output),
but any suffix is allowed. One file may contain one or more
variables of different kind. The time step is regular along one file.
The first lines of file contains information about file content, without a specific order or format.
A section identified by the keyword data follows.
It marks the beginning of time series data. The first
line after the data keyword is a comment line usually used to
mark the content of each column in the file. Data are separated
by one or more blank spaces or tabs. A dot (.) is used as decimal separator.
The next example shows a time series file that contains average precipitation and air temperature over the Piave river at Longarone.
Example of generic variables time series file
spatial average values of meteorological variables
extent id: 01
extent name: longarone
extent area (km2): 1328.18872
number of variables: 2
data
DateTime precipitation_mm air-temperature_Celsius
2018-10-15T00:00:00+00:00 0.00000E+00 0.34635E+01
2018-10-15T01:00:00+00:00 0.00000E+00 0.35652E+01
2018-10-15T02:00:00+00:00 0.00000E+00 0.33697E+01
2018-10-15T03:00:00+00:00 0.00000E+00 0.35632E+01
2018-10-15T04:00:00+00:00 0.00000E+00 0.38865E+01
2018-10-15T05:00:00+00:00 0.00000E+00 0.39953E+01
2018-10-15T06:00:00+00:00 0.12359E-02 0.41558E+01
2018-10-15T07:00:00+00:00 0.13124E-02 0.46632E+01
2018-10-15T08:00:00+00:00 0.00000E+00 0.53044E+01
2018-10-15T09:00:00+00:00 0.00000E+00 0.61314E+01
2018-10-15T10:00:00+00:00 0.41156E-02 0.64432E+01
2018-10-15T11:00:00+00:00 0.18876E-01 0.67689E+01
2018-10-15T12:00:00+00:00 0.37281E-01 0.63840E+01
1.6. Tables#
Tables are used to organize information with column information in the header and one line of data per record. Tables are stored on plain text files. They are formatted according to a standard that takes inspiration from the ODT file format (http://math.nist.gov/oommf/doc/userguide11b2/userguide/Data_table_format_ODT.html).
Tables can be used within a ini configuration file (see Chapter 2) or within a file that contain only tables. In this case, it is recommended that files be given names ending in the file extension .tab so that table files can be easily identified. Every file can contain one or more tables. Table may contain an unlimited number of columns and lines. An header and a unit is associated to each column. Hash # indicates the beginning of a comment. Table may contain blank lines.
The lines of a table should be comments, data, or any of the following 5 recognized descriptor tag lines:
Table Start: mandatory, used to mark the beginning of a new table.Title:optional; everything after the colon is interpreted as a title for the table.Id:mandatory; an alphanumeric string that define uniquely the table.Columns:mandatory. One parameter per column, enclosed between two square brackets [ ].Units:mandatory. One parameter for each column, enclosed between two square brackets [ ], giving a unit label for the corresponding column.Table End: mandatory, no parameters. Should be paired with a corresponding Table Start record to mark the end of the table.
Data may appear anywhere after the Units descriptor record and before any Table End line, with one record per line. The data should be numeric values or string separated by whitespace.
Example of table
Table Start
Title: This is a small example of table
# This is a sample comment. You can put anything you want
# on comment lines.
Id: type here Id of table # example of inline comment
Columns: [header1] [header2] [header3]
Units: [-] [-] [m3/s]
1 name1 13.2
2 name2 10.8
3 name3 5.35
# this is a comment: the above line is blank
Table End